What is Data Ingestion in Informatica Intelligent Data Management Cloud (IDMC) ? Are you also interested in knowing what are the features of features and benefits of the Data Ingestion process? If so, then you reached the right place. In this article, we will understand details about Data Ingestion in Informatica Intelligent Data Management Cloud (IDMC).
Data Ingestion in IDMC:
Data ingestion is the process of collecting and importing data from various sources into a target system. Informatica Intelligent Data Management Cloud (IDMC) is a comprehensive data management platform that enables organizations to ingest, process, and manage data from various sources. In this article, we will explore the data ingestion capabilities of IDMC and how it can help organizations streamline their data ingestion process.
IDMC provides several options for data ingestion, including file-based ingestion, database ingestion, and API ingestion. Let's take a closer look at each of these options.
A) File-Based Ingestion
IDMC allows users to ingest data from various file formats such as CSV, XML, JSON, Excel, and many more. Users can set up a file-based ingestion task by creating a new data ingestion task and configuring the source and target locations. Once the configuration is complete, IDMC will automatically ingest the data from the source location and load it into the target system.
B) Database Ingestion
IDMC also supports database ingestion from various relational databases such as Oracle, SQL Server, MySQL, and many more. Users can set up a database ingestion task by configuring the source database connection details and selecting the target system. IDMC will automatically generate the necessary SQL queries and execute them to transfer the data from the source database to the target system.
C) API Ingestion
IDMC also provides an API-based ingestion option that allows users to ingest data from various web services and APIs. Users can set up an API ingestion task by configuring the API endpoint and authentication details. IDMC will automatically retrieve the data from the API endpoint and load it into the target system.
Data Ingestion involves various processes and these are
1. Data Preparation: Before ingesting data, IDMC provides several data preparation features to ensure that the data is clean and ready for ingestion. These features include data profiling, data cleansing, data masking, and more.
2. Data Mapping: IDMC provides a drag-and-drop interface for data mapping, allowing users to map the source data to the target system. The data mapping process is intuitive and easy to use, reducing the time and effort required to configure the ingestion task.
3. Change Data Capture (CDC): IDMC supports CDC, which enables organizations to capture only the changes made to the source data since the last ingestion. This capability reduces the amount of data that needs to be ingested, improving the efficiency of the data ingestion process.
4. Data Validation: IDMC provides data validation features that ensure that the ingested data meets the expected quality standards. These features include data validation rules, data profiling, and more.
5. Real-Time Monitoring: IDMC provides real-time monitoring features that allow users to monitor the status of the ingestion tasks and receive alerts if any issues arise. This capability enables organizations to quickly identify and resolve any issues that may arise during the ingestion process.
6. Metadata Management: IDMC provides metadata management features that enable users to manage the metadata associated with the ingested data. This capability provides insights into the data lineage, data quality, and data governance.
Data ingestion is a complex process that requires a comprehensive platform to manage effectively. IDMC provides a flexible, scalable, and secure platform that enables organizations to ingest, process, and manage data from various sources. With its data preparation, data mapping, CDC, data validation, real-time monitoring, and metadata management features, IDMC streamlines the data ingestion process and maximizes the value of the ingested data.
Benefits of Data Ingestion in IDMC
Here are some of the benefits of using IDMC for data ingestion:
a) Flexibility: IDMC provides various options for data ingestion, allowing organizations to ingest data from a variety of sources.
b) Automation: IDMC automates the data ingestion process, reducing the need for manual intervention and minimizing the risk of errors.
c) Scalability: IDMC can handle large volumes of data, making it suitable for organizations that need to process and manage large amounts of data.
d) Data Quality: IDMC includes data quality features such as data profiling and cleansing, ensuring that the ingested data is accurate and consistent.
In addition to the benefits mentioned above, IDMC also provides several other advantages for data ingestion. Let's take a look at some of them.
Integration with Other IDMC Services: IDMC provides integration with other services such as data integration, data quality, data cataloging, and more. This integration allows organizations to streamline the entire data management process, from data ingestion to data consumption.
Real-time Data Ingestion: IDMC supports real-time data ingestion, allowing organizations to ingest data as it is generated. This capability is particularly useful for applications that require real-time data processing, such as IoT or real-time analytics.
Security and Compliance: IDMC provides robust security and compliance features, ensuring that the ingested data is protected from unauthorized access and meets regulatory compliance requirements.
Data Lineage: IDMC provides data lineage features that track the flow of data from its source to the target system. This capability allows organizations to understand where the data comes from and how it is used, providing insights into data quality and governance.
Cloud-Based: IDMC is a cloud-based platform, providing scalability, flexibility, and cost-efficiency. Organizations can leverage the cloud to scale up or down their data ingestion needs, pay only for what they use, and reduce their infrastructure costs.
In conclusion, Data ingestion is a critical component of any data management strategy. IDMC provides a comprehensive platform for data ingestion, allowing organizations to ingest, process, and manage data from various sources. Whether you need to ingest data from files, databases, or APIs, IDMC provides the flexibility and automation needed to streamline the process and ensure data quality.
Are you planning to implement Microservices in your project? Are you looking for details about what are the different Microservices patterns? If so, then you reached the place. In this article, we will understand various Microservices patterns in detail. Let's start
Introduction
Microservices architecture is a popular software development approach that emphasizes the creation of small, independent services that can work together to deliver a larger application or system. This approach has become popular due to the flexibility, scalability, and maintainability it offers. However, designing and implementing a microservices-based system can be challenging. To help address these challenges, developers have come up with various patterns for designing and implementing microservices. In this article, we'll discuss some of the most common microservices patterns.
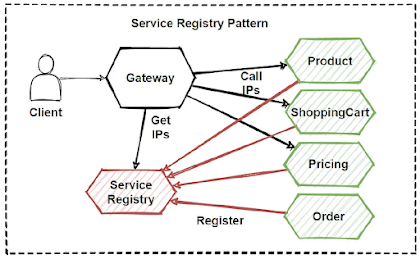
1. Service Registry Pattern
The service registry pattern involves using a centralized registry to keep track of all available services in a system. Each service registers itself with the registry and provides metadata about its location and capabilities. This enables other services to discover and communicate with each other without having to hardcode the location of each service.
2. API Gateway Pattern
The API gateway pattern involves using a single entry point for all client requests to a system. The gateway then routes requests to the appropriate microservice based on the request type. This pattern simplifies client access to the system and provides a layer of abstraction between clients and microservices.
3. Circuit Breaker Pattern
The circuit breaker pattern involves using a component that monitors requests to a microservice and breaks the circuit if the microservice fails to respond. This prevents cascading failures and improves system resilience.
4. Event Sourcing Pattern
The event sourcing pattern involves storing all changes to a system's state as a sequence of events. This enables the system to be reconstructed at any point in time and provides a reliable audit trail of all changes to the system.
5. CQRS Pattern
The CQRS (Command Query Responsibility Segregation) pattern involves separating read and write operations in a system. This enables the system to optimize for each type of operation and improves system scalability and performance.
5. Saga Pattern
The saga pattern involves using a sequence of transactions to ensure consistency in a distributed system. Each transaction is responsible for a specific task and can be rolled back if an error occurs. This pattern is useful for long-running transactions that involve multiple microservices.
6. Bulkhead Pattern
The bulkhead pattern involves isolating microservices in separate threads or processes to prevent failures in one microservice from affecting others. This pattern improves system resilience and availability.
In conclusion, microservices patterns are essential for designing and implementing scalable, maintainable, and resilient microservices-based systems. The patterns discussed in this article are just a few of the many patterns available, but they are some of the most common and widely used. By understanding and using these patterns, developers can create microservices-based systems that are easier to develop, deploy, and maintain.
If you are planning to implement Informatica Master Data Management in your organization and you would like to know what are the issues normally get identified during MDM project implementation? If yes, then you reached the right place. In this article, we will understand all the major issues which normally occur during MDM implementation. We will also see how to address MDM issues in detail.
Lack of Data Quality Checks: The Importance of Validating Data in Informatica MDM
Data quality is an essential aspect of any master data management (MDM) project. Poor data quality can lead to incorrect decisions, inaccurate analysis, and an overall decrease in the effectiveness of the MDM system. In Informatica MDM, a lack of data quality checks can result in critical errors that can affect the entire data ecosystem.
To address this issue, it is necessary to implement a rigorous data validation process. This process should include data profiling, data cleansing, and data enrichment. Data profiling involves examining the data to identify its quality, consistency, completeness, and accuracy. Data cleansing refers to the process of removing or correcting errors in the data, such as duplicates, incomplete data, or incorrect data types. Data enrichment involves adding new data to the existing data set to improve its quality or completeness.
In addition to these processes, it is crucial to establish data quality metrics and implement data quality rules. Data quality metrics can help measure the effectiveness of the data validation process and identify areas that need improvement. Data quality rules can help ensure that the data meets certain standards, such as format, completeness, and accuracy.
To ensure that data quality checks are effective, it is essential to involve all stakeholders, including business users, data analysts, and data stewards, in the process. Business users can help define the data quality requirements, while data analysts can help design the data validation process. Data stewards can help enforce the data quality rules and ensure that the data is maintained at a high standard.
In conclusion, a lack of data quality checks can have serious consequences for Informatica MDM projects. To ensure that the data is accurate, complete, and consistent, it is essential to implement a rigorous data validation process that includes data profiling, data cleansing, and data enrichment. By involving all stakeholders and implementing data quality metrics and rules, organizations can ensure that their Informatica MDM system is effective and reliable.
Mismatched Data Models: Addressing the Issue of Incompatible Data Structures in Informatica MDM
One of the critical errors that can occur in Informatica MDM projects is mismatched data models. This occurs when the data models used in different systems are incompatible with each other, leading to data inconsistencies, errors, and misinterpretation. Mismatched data models can result in incorrect analysis, decision-making, and ultimately, a decrease in the effectiveness of the MDM system.
To address this issue, it is essential to establish a standard data model that can be used across all systems. The data model should be designed to be flexible, scalable, and adaptable to the changing needs of the organization. It should also be designed to integrate easily with existing systems and applications.
Another critical aspect of addressing mismatched data models is data mapping. Data mapping involves translating the data structures used in different systems into a common data model. This process can be complex and requires careful consideration of the data structures used in each system.
To ensure that data mapping is accurate and effective, it is necessary to involve all stakeholders in the process. This includes business users, data analysts, and data stewards. Business users can help define the data mapping requirements, while data analysts can help design the data mapping process. Data stewards can help ensure that the data mapping is accurate and that the data is maintained at a high standard.
Finally, it is essential to establish data governance policies and procedures to ensure that the data is managed effectively across all systems. This includes policies on data ownership, data access, data security, and data quality. Data governance policies should be designed to ensure that the data is consistent, accurate, and secure and that it meets the needs of the organization.
In conclusion, mismatched data models can be a significant issue in Informatica MDM projects, leading to data inconsistencies and errors. To address this issue, it is necessary to establish a standard data model, design an effective data mapping process, involve all stakeholders in the process, and establish effective data governance policies and procedures. By doing so, organizations can ensure that their Informatica MDM system is effective and reliable.
Incomplete Data Governance: The Consequences of Inadequate Data Management Practices in Informatica MDM
Data governance is the process of managing the availability, usability, integrity, and security of the data used in an organization. In Informatica MDM projects, incomplete data governance can have serious consequences, including data inconsistencies, errors, and misinterpretation. Inadequate data governance can also lead to security breaches, regulatory violations, and reputational damage.
To address this issue, it is necessary to establish a comprehensive data governance framework that includes policies, processes, and procedures for managing data effectively. The data governance framework should be designed to ensure that the data is consistent, accurate, and secure and that it meets the needs of the organization.
One critical aspect of data governance is data ownership. Data ownership refers to the responsibility for managing and maintaining the data within the organization. It is essential to establish clear data ownership roles and responsibilities to ensure that the data is managed effectively. Data ownership roles and responsibilities should be assigned to individuals or departments within the organization based on their knowledge and expertise.
Another critical aspect of data governance is data access. Data access refers to the ability to access and use the data within the organization. It is necessary to establish clear data access policies and procedures to ensure that the data is accessed only by authorized individuals or departments. Data access policies and procedures should also include measures to prevent unauthorized access, such as access controls and user authentication.
Data security is another critical aspect of data governance. Data security refers to the protection of the data from unauthorized access, use, or disclosure. It is essential to establish clear data security policies and procedures to ensure that the data is protected from security breaches, such as data theft or hacking. Data security policies and procedures should include measures such as encryption, data backups, and disaster recovery plans.
In conclusion, incomplete data governance can have serious consequences for Informatica MDM projects. To address this issue, it is necessary to establish a comprehensive data governance framework that includes policies, processes, and procedures for managing data effectively. This framework should include clear data ownership roles and responsibilities, data access policies and procedures, and data security policies and procedures. By doing so, organizations can ensure that their Informatica MDM system is effective and reliable.
Poor Data Mapping: The Pitfalls of Incorrectly Mapping Data in Informatica MDM
Data mapping is the process of transforming data from one format or structure to another. In Informatica MDM projects, poor data mapping can result in inaccurate or incomplete data, which can lead to errors, misinterpretations, and poor decision-making. To address this issue, it is necessary to establish effective data mapping processes and procedures.
One of the primary challenges of data mapping in Informatica MDM projects is the complexity of the data. In many cases, the data used in Informatica MDM projects are spread across multiple systems, and each system may have its own unique data structure. This can make it difficult to create accurate and effective data mappings.
To address this challenge, it is essential to involve all stakeholders in the data mapping process. This includes business users, data analysts, and data stewards. Business users can help define the data mapping requirements, while data analysts can help design the data mapping process. Data stewards can help ensure that the data mapping is accurate and that the data is maintained at a high standard.
Another critical aspect of effective data mapping is the use of data quality tools and processes. Data quality tools can help identify data inconsistencies, errors, and duplicates, which can be corrected during the data mapping process. Data quality processes should also be established to ensure that the data is maintained at a high standard throughout the data mapping process.
Finally, it is essential to establish data governance policies and procedures to ensure that the data is managed effectively across all systems. This includes policies on data ownership, data access, data security, and data quality. Data governance policies should be designed to ensure that the data is consistent, accurate, and secure and that it meets the needs of the organization.
In conclusion, poor data mapping can be a significant issue in Informatica MDM projects, leading to inaccurate or incomplete data, errors, misinterpretations, and poor decision-making. To address this issue, it is necessary to involve all stakeholders in the data mapping process, use data quality tools and processes, and establish effective data governance policies and procedures. By doing so, organizations can ensure that their Informatica MDM system is effective and reliable.
Inadequate Data Security: The Risks of Insufficient Data Protection in Informatica MDM
Data security is a critical concern in Informatica MDM projects. Inadequate data security can lead to data breaches, unauthorized access, data corruption, and other security risks, which can have severe consequences for the organization. To address this issue, it is necessary to establish effective data security policies and procedures.
One of the primary concerns in data security is data access. Data access refers to the ability to access and use the data within the organization. To ensure data security, it is essential to establish clear data access policies and procedures. Data access policies should be designed to ensure that the data is accessed only by authorized individuals or departments. This can be achieved by implementing access controls, user authentication, and user authorization.
Another critical aspect of data security is data storage. Data storage refers to the physical and logical storage of data within the organization. It is essential to ensure that the data is stored in a secure location, and that access to the data is restricted. This can be achieved by implementing data encryption, data backup, and disaster recovery plans.
Data security policies should also include measures to prevent data breaches and unauthorized access. This can be achieved by implementing data monitoring, data auditing, and data encryption. Data monitoring and auditing can help detect and prevent security breaches, while data encryption can help protect data from unauthorized access.
Finally, it is essential to establish data governance policies and procedures to ensure that the data is managed effectively across all systems. This includes policies on data ownership, data access, data security, and data quality. Data governance policies should be designed to ensure that the data is consistent, accurate, and secure and that it meets the needs of the organization.
In conclusion, inadequate data security can have serious consequences for Informatica MDM projects. To address this issue, it is necessary to establish effective data security policies and procedures. This includes implementing clear data access policies, ensuring secure data storage, and implementing measures to prevent data breaches and unauthorized access. By doing so, organizations can ensure that their Informatica MDM system is secure and reliable.
Over-Reliance on Automated Processes: The Dangers of Relying Too Heavily on Automation in Informatica MDM
Automation has become an essential aspect of modern business processes, and this is no exception in Informatica MDM. However, over-reliance on automated processes can pose significant risks to an organization. While automation can improve efficiency and accuracy, it is not a substitute for human judgment and decision-making.
One of the primary risks of over-reliance on automated processes is that it can lead to inaccurate or incomplete data. Automated processes are designed to follow predefined rules and procedures, and if these rules and procedures are not accurate or complete, the resulting data can be incorrect. This can lead to errors, misinterpretations, and poor decision-making.
To address this issue, it is necessary to establish effective data governance policies and procedures. Data governance policies should be designed to ensure that the data is consistent, accurate, and secure and that it meets the needs of the organization. This includes policies on data ownership, data access, data security, and data quality.
Another risk of over-reliance on automated processes is that it can lead to a lack of flexibility. Automated processes are designed to follow predefined rules and procedures, and if these rules and procedures do not allow for flexibility, the resulting data can be limited. This can make it difficult to adapt to changing business requirements or to respond to unexpected events.
To address this issue, it is necessary to involve all stakeholders in the design and implementation of automated processes. This includes business users, data analysts, and data stewards. Business users can help define the business requirements, while data analysts can help design automated processes. Data stewards can help ensure that the data is maintained at a high standard and that the automated processes are flexible enough to meet changing business requirements.
Finally, it is essential to ensure that there is appropriate oversight of automated processes. This includes monitoring and auditing the automated processes to ensure that they are functioning correctly and that the data is accurate and complete. It also includes establishing procedures for correcting errors or inconsistencies in the data.
In conclusion, over-reliance on automated processes can pose significant risks to Informatica MDM projects. To address this issue, it is necessary to establish effective data governance policies and procedures, involve all stakeholders in the design and implementation of automated processes, and ensure that there is appropriate oversight of these processes. By doing so, organizations can ensure that their Informatica MDM system is effective, reliable, and flexible.
Are you looking for the details Informatica Intelligent Data Management Cloud (IDMC)? Earlier it is called Informatica Intelligent Cloud Services (IICS). Are you also interested in knowing the features of Informatica Intelligent Data Management Cloud (IDMC) ? If so, you reached at right place. In this article, we will understand the features of Informatica Intelligent Data Management Cloud (IDMC).
Intelligent Data Management Cloud (IDMC) is a cloud-based solution for managing and analyzing data. Some of the features of IDMC include:
Data ingestion: Ability to import data from various sources, including databases, cloud storage, and file systems.
Data cataloging: IDMC automatically catalogs and classifies data, making it easier to discover, understand and manage.
Data governance: IDMC provides robust data governance features, including data privacy and security, data lineage, and data quality.
Data analytics: IDMC includes advanced analytics capabilities, such as machine learning, data visualization, and business intelligence.
Data collaboration: IDMC enables data collaboration among teams and organizations, providing a centralized location for data discovery, sharing and management.
Multi-cloud support: IDMC supports multi-cloud environments, allowing organizations to manage their data across multiple cloud platforms.
Scalability: IDMC is designed to scale with your organization's data growth, allowing for seamless data management as data volumes increase.
Multi-cloud support is one of the key features of Intelligent Data Management Cloud (IDMC). Multi-cloud support refers to the ability to manage and analyze data across multiple cloud platforms. With multi-cloud support, organizations can:
Centralize data management: IDMC provides a centralized platform for managing and analyzing data from different cloud platforms, making it easier to gain insights and make data-driven decisions.
Avoid vendor lock-in: By managing data across multiple cloud platforms, organizations can reduce the risk of vendor lock-in and have greater flexibility in their choice of cloud provider.
Optimize costs: IDMC allows organizations to take advantage of the best cost and performance options available from different cloud platforms, helping to optimize their overall cloud costs.
Improve data accessibility: IDMC enables data to be accessed and shared across different cloud platforms, improving data accessibility and collaboration among teams.
Ensure data security: IDMC provides robust data security features, such as encryption, access controls, and audit trails, to ensure the security of data stored in multiple cloud platforms
Multi-cloud support is becoming increasingly important as more organizations adopt cloud computing and seek to manage and analyze their data across different cloud platforms. IDMC provides a centralized solution for managing data across multiple cloud platforms, making it easier to gain insights and make data-driven decisions.
Would you be interested in knowing what causes ORA-12154 error and how to resolve it? Are you also interested in knowing important tips in order to resolve ORA-12154 error? If so, then you reached the right place. In this article, we will understand how to fix this error. Let's start.
What is ORA-12154 error in Oracle database?
ORA-12154: TNS could not resolve service name is a common error encountered while connecting to an Oracle database. This error occurs when the TNS (Transparent Network Substrate) service is unable to find the service name specified in the connection string.
Here are some tips to resolve the ORA-12154 error:
Check the TNSNAMES.ORA file: This file is used by TNS to resolve the service name to an actual database connection. Check the file for any spelling or syntax errors in the service name.
Verify the service name: Make sure that the service name specified in the connection string matches the service name defined in the TNSNAMES.ORA file.
Update the TNS_ADMIN environment variable: If you are using a different TNSNAMES.ORA file, make sure that the TNS_ADMIN environment variable points to the correct location.
Check the listener status: Ensure that the listener is running and able to accept incoming connections. You can check the listener status by using the “lsnrctl status” command.
Restart the listener: If the listener is not running, restart it using the “lsnrctl start” command.
Check the network connectivity: Verify that the server hosting the database is reachable and there are no network issues preventing the connection.
Reinstall the Oracle client: If all other steps fail, reinstalling the Oracle client may resolve the ORA-12154 error.
Verify the Oracle Home environment variable: Make sure that the Oracle Home environment variable is set correctly to the location of the Oracle client software.
Check the SQLNET.ORA file: This file is used to configure the Oracle Net Services that provide the communication between the client and the server. Verify that the correct settings are configured in the SQLNET.ORA file.
Use the TNS Ping utility: The TNS Ping utility is used to test the connectivity to the database by checking the availability of the listener. You can use the “tnsping” command to run this utility.
Check the firewall settings: If the server hosting the database is located behind a firewall, verify that the firewall is configured to allow incoming connections on the specified port.
Disable the Windows Firewall: If the Windows firewall is enabled, it may be blocking the connection to the database. Try disabling the Windows firewall temporarily to see if it resolves the ORA-12154 error.
Check the port number: Make sure that the port number specified in the connection string matches the port number used by the listener.
Try a different connection method: If the error persists, try connecting to the database using a different method such as SQL*Plus or SQL Developer.
Check for multiple TNSNAMES.ORA files: If you have multiple Oracle client installations on the same machine, there may be multiple TNSNAMES.ORA files. Make sure you are using the correct TNSNAMES.ORA file for your current Oracle client installation.
Check the service name format: The service name can be specified in different formats such as a simple string, an easy connect string, or a connect descriptor. Make sure that you are using the correct format for your particular scenario.
Upgrade the Oracle client software: If you are using an outdated version of the Oracle client software, upgrading to the latest version may resolve the ORA-12154 error.
Check for incorrect hostname or IP address: Verify that the hostname or IP address specified in the connection string is correct and matches the actual hostname or IP address of the database server.
Verify the SERVICE_NAME parameter in the database: If you are connecting to a database that uses the SERVICE_NAME parameter instead of the SID, make sure that the service name specified in the connection string matches the actual service name in the database.
Check the network configuration: If you are using a complex network configuration such as a VPN, make sure that the network is configured correctly and that the database server is accessible from the client machine.
Verify that LDAP is listed as one of the values of the names.directory_path parameter in the sqlnet.ora Oracle Net profile.
Verify that the LDAP directory server is up and that it is accessible.
Verify that the net service name or database name used as the connect identifier is configured in the directory.
Verify that the default context being used is correct by specifying a fully qualified net service name or a full LDAP DN as the connect identifier
By following these tips, you should be able to resolve the ORA-12154 error and successfully connect to your Oracle database. If the error persists, it is important to seek the help of a qualified Oracle database administrator or support specialist.
Are you looking for what is best way to fix Null Pointer error in your Java code? Are also would like to know what causes Null Pointer error. If so, then you reached at right place. In this article, we will understand what is root cause of Null Pointer error and how to fix it. Let's start.
A null pointer error, also known as a "null reference exception," occurs when a program attempts to access an object or variable that has a null value. In other words, the program is trying to access an object that doesn't exist. This can happen when a variable is not initialized or is set to null, but the program tries to access it as if it has a value.
The error message will typically indicate the specific location in the code where the error occurred, and it will look something like this: "java.lang.NullPointerException at [classname].[methodname]([filename]:[line number])".
There are several ways to fix a null pointer error, but the most common solution is to check for null values before trying to access an object. This can be done by using an if statement to check if the variable is null, and if so, assign a value to it or handle the error in a specific way.
Another way is to use the "Optional" class introduced in Java 8, it allows to avoid null pointer exceptions. It can be used with any type of variable and it wraps the variable and it can check if it's present or not.
For example, if the error occurs when trying to access an object called "objectName," the following code can be used to fix it:
if (objectName != null) {
// code to access objectName
} else {
// handle the error or assign a value to objectName
}
Additionally, you should check that the objects that you're using are not null, it's also important to check that the objects that the object you're using is not null. To avoid this error, it's important to initialize variables and objects properly and to be aware of the scope of the variables and objects that you're using in your code.
In summary, a null pointer error occurs when a program tries to access an object or variable that has a null value. The error can be fixed by checking for null values before trying to access an object and handling the error properly. It is important to initialize the variables and objects properly, check for the scope of the variables and objects, and to be aware of the potential of null values.
Data governance is the set of processes, programs, and norms that associations use to insure the quality, vacuity, and security of their data. It involves a
range of conditioning, including data operation, data quality assurance, data security, and compliance.
One of the main pretensions of data governance is to insure that data is accurate,
harmonious, and dependable. This
is fulfilled through data operation practices similar to data confirmation, data sanctification, and data standardization.
Data quality assurance is also an important aspect of data governance, as it
helps to identify and correct crimes or
inconsistencies in the data. Another
important aspect of data governance is data security. Organizations must insure that their data is defended from unauthorized access, as well as
from accidental or purposeful breaches.
This can include enforcing security
controls similar to firewalls, intrusion
discovery systems, and encryption.
Compliance is also a major concern for associations, as they must cleave
to a variety of laws and regulations that govern the use and running of data.
This can include regulations similar to the General Data Protection Regulation( GDPR) in the European
Union and the Health Insurance Portability and Responsibility Act( HIPAA) in
the United States. Organizations must insure that their data governance practices align with these regulations
to avoid expensive forfeitures and penalties. Data governance is a critical aspect of any
association's operations, as it helps to insure the quality, vacuity, and security of their data. It involves a
range of conditioning, including data operation, data quality assurance, data security, and compliance.
By enforcing
effective data governance practices, associations can ameliorate their
decision-making capabilities, cover
their character, and achieve compliance with laws and regulations. enforcing data governance can be a complex
process, as it involves numerous
different stakeholders and can have a significant impact on an association's
operations. thus, it's important to have a clear and well-defined data
governance framework in place.
This frame should
include the places and liabilities of the colorful stakeholders, as well as the programs and procedures that will be used to
govern the data. One of the crucial factors of data governance is a data governance council. This council is
responsible for creating and administering the data governance programs and procedures. It should be made up
of representatives from colorful
departments within the association,
similar to IT, legal, and compliance. This will insure that all stakeholders have a voice in
the data governance process and that the programs and procedures are aligned with the overall pretensions of the association.
Another important
aspect of data governance is data governance software. This software can
automate numerous data governance
processes, similar to data confirmation, data sanctification, and data standardization. It
can also help to cover the data to insure compliance with laws and regulations. also, it can give real-time visibility into the data,
which can help associations to identify issues and take corrective action
more snappily. Data Governance isn't a one-time event, it
requires ongoing monitoring and conservation to insure that the
data is accurate, harmonious, and
secure. Regular checkups should be
conducted to insure that the data
governance programs and procedures are
being followed and to identify any areas for enhancement.
In conclusion, data
governance is a critical aspect of any association's operations. It helps
to insure the quality, vacuity, and
security of the data, which is essential for effective decision- timber,
guarding character, and achieving compliance. Organizations should apply a clear and well-defined data
governance frame, including a data
governance council and data governance software to automate processes. Regular
monitoring and conservation are
also crucial to icing the ongoing effectiveness of data
governance practices.