Informatica Zero Downtime is a feature provided by Informatica, a leading data integration and management software company. Zero Downtime refers to the ability to perform maintenance tasks, upgrades, or migrations on a system without any disruption to the ongoing operations or availability of the system.
With Informatica Zero Downtime, organizations can ensure continuous data integration, data migration, and other critical operations without any scheduled or unplanned interruptions. This feature is particularly useful for businesses that require high availability and cannot afford to have downtime that may impact their operations, customer experience, or revenue.
Informatica achieves Zero Downtime through various techniques and strategies. These include:
Active-active clustering:
Informatica PowerCenter, the flagship product of Informatica, supports active-active clustering configurations, where multiple instances of the PowerCenter server are deployed across different nodes. This allows for load balancing and failover capabilities, ensuring uninterrupted service in case of node failures or maintenance activities.
Rolling upgrades:
Informatica supports rolling upgrades, which means that upgrades or updates can be applied to different components of the system (such as servers, services, or repositories) in a sequential manner while the system remains operational. This approach minimizes or eliminates the downtime associated with upgrading the entire system at once.
High availability architecture:
Informatica provides features and configurations to set up a high availability architecture, including redundant components and failover mechanisms. This ensures that if one component fails, another takes over seamlessly, thereby preventing service disruption.
Data replication and synchronization:
Informatica supports data replication and synchronization mechanisms to ensure that data remains consistent and available during maintenance activities. This allows businesses to continue processing and accessing data without interruption.
By leveraging these techniques and features, Informatica enables organizations to achieve zero downtime during critical operations such as upgrades, migrations, or maintenance tasks. This ensures continuous data integration and availability, minimizing disruptions and maximizing productivity.
Do you know what are leading top 10 Master Data Management solutions in current market? Are you interested in knowing it? If so, then you reached right place. In this article, we will list top 10 MDM cloud solutions.
Here are 10 popular Master Data Management (MDM) cloud solutions:
Informatica MDM Cloud: Informatica's MDM Cloud is a comprehensive solution that offers features like data integration, data quality, master data governance, and data stewardship.
Oracle Customer Data Management (CDM) Cloud: Oracle CDM Cloud provides a complete MDM solution for managing customer data, including customer profiles, hierarchies, and relationships.
IBM Master Data Management on Cloud: IBM's MDM on Cloud is a flexible and scalable solution that enables organizations to manage master data across multiple domains, such as customer, product, and supplier.
SAP Master Data Governance (MDG) Cloud: SAP MDG Cloud is a cloud-based MDM solution that helps businesses establish and maintain consistent, accurate, and reliable master data across their enterprise systems.
Reltio Cloud: Reltio Cloud is a modern MDM platform that combines master data management with real-time data integration and data-driven applications for better customer experiences and operational efficiency.
Talend Cloud MDM: Talend Cloud MDM is a cloud-based MDM solution that enables organizations to integrate, manage, and govern their master data across on-premises and cloud applications.
Stibo Systems STEP Trailblazer: STEP Trailblazer by Stibo Systems is a cloud-native MDM platform that offers robust capabilities for managing master data, product information, digital assets, and more.
TIBCO EBX: TIBCO EBX is a cloud-based MDM solution that provides a single view of master data across domains and applications, helping organizations make better decisions based on accurate and consistent data.
Profisee: Profisee is a cloud-based MDM platform that offers a user-friendly interface, data stewardship capabilities, and comprehensive data management features to ensure high-quality master data.
EnterWorks Enable: EnterWorks Enable is a cloud-based MDM solution that enables organizations to create and manage a single, trusted view of their master data across channels, departments, and systems.
These are just a few examples of popular MDM cloud solutions available in the market. It's important to evaluate each solution based on your specific requirements, industry needs, and integration capabilities with your existing systems before making a decision.
The error message "No cluster leader" in EDC (Enterprise Data Catalog) for Informatica indicates that the Nomad service, which is responsible for managing the cluster and coordination among nodes, is unable to identify a leader node within the cluster. This error typically occurs when there is a problem with the cluster configuration or the availability of the leader node.
To troubleshoot and resolve this error, you can follow these steps:
Verify network connectivity: Ensure that all the nodes in the cluster can communicate with each other. Check if there are any network connectivity issues or firewall restrictions that might be preventing communication.
Check Nomad service status: Verify the status of the Nomad service on each node of the cluster. Ensure that the Nomad service is running and healthy on all nodes. You can use commands like systemctl status nomad or service nomad status to check the status.
Review Nomad configuration: Examine the Nomad configuration files on each node, typically located in the /etc/nomad/ directory. Pay attention to the cluster configuration settings, such as the addresses of other cluster nodes, leader election parameters, and any authentication or encryption settings. Ensure that the configuration is accurate and consistent across all nodes.
Check for cluster inconsistencies: If the cluster configuration appears to be correct, investigate for any inconsistencies or issues within the cluster. Review the logs of each node to identify any error messages or warnings related to Nomad or cluster coordination. Look for any network partitioning or connectivity problems between nodes.
Restart Nomad service: If there are no apparent configuration or cluster issues, try restarting the Nomad service on all nodes of the cluster. This can help refresh the cluster state and trigger leader election. Use commands like systemctl restart nomad or service nomad restart to restart the service.
Root cause:
The Nomad service may fail with following error when we update IP addresses of cluster nodes
T16:14:25.145Z [ERROR] client.rpc: error performing RPC to server: error="rpc error: No cluster leader" rpc=Node.Register server=xxxx
T16:14:25.145Z [ERROR] client: error registering: error="rpc error: No cluster leader"
T16:14:25.489Z [ERROR] client.rpc: error performing RPC to server: error="rpc error: No cluster leader" rpc=Node.UpdateAlloc server=xxx
Normally, such an error occurs when we deploy Enterprise Data Catalog in containers such as Docker. The image will run on a new IP address when we re-deploy an image, whereas the Nomad cache contains the IP address from the earlier deployment.
Solution:
For a new deployment, to delete the cache files that store the IP address, perform the following steps:
Delete the $clusterCustomDir/nomad/nomadserver/server/ directory.
Informatica Cloud Customer 360 and Informatica Cloud Multidomain MDM are two different offerings from Informatica, a company that provides data management solutions. Here are the key differences between the two:
Informatica Cloud Customer 360:
Focus: Informatica Cloud Customer 360 is specifically designed for customer data management. It helps organizations consolidate, cleanse, and enrich customer data from various sources to create a unified, 360-degree view of customers.
Functionality: It provides capabilities for data integration, data quality, data mastering, and data synchronization to ensure accurate and up-to-date customer information across systems and applications.
Use cases: Informatica Cloud Customer 360 is commonly used by businesses that need to improve customer experiences, enhance marketing campaigns, enable personalized services, and achieve a single, trusted view of their customers.
Target audience: The primary users of Informatica Cloud Customer 360 are marketing, sales, and customer service along with IT, and governance teams within organizations.
Informatica Cloud Multidomain MDM:
Scope: Informatica Cloud Multidomain MDM offers broader master data management (MDM) capabilities and is not limited to customer data alone. It enables organizations to manage and govern master data across multiple domains, such as customers, products, suppliers, employees, and more.
Functionality: It provides comprehensive data management features for data integration, data quality, data governance, data stewardship, and data synchronization to ensure consistency and accuracy of master data across diverse systems.
Use cases: Informatica Cloud Multidomain MDM is useful for organizations that need to establish a centralized and authoritative source of master data across multiple business domains, ensuring data consistency, compliance, and improved decision-making.
Target audience: The primary users of Informatica Cloud Multidomain MDM are data management, IT, and governance teams responsible for managing and governing master data across various domains within an organization.
In summary, Informatica Cloud Customer 360 is specifically tailored for customer data management, while Informatica Cloud Multidomain MDM offers broader capabilities for managing master data across multiple domains. The choice between the two depends on the specific data management needs of an organization.
Snowflake, the cloud data platform, offers powerful data warehousing and analytics capabilities. However, like any complex system, it may encounter errors from time to time. One such error is the HTTP response code 422, which is accompanied by a QueryFailureStatus object. In this article, we will explore the causes of this error and provide steps to resolve it effectively.
The HTTP response code 422 in Snowflake signifies an Unprocessable Entity error. It indicates that the server understands the request made by the client but cannot process it due to a semantic error. When this error occurs, Snowflake provides additional details in the form of a QueryFailureStatus object, which contains information about the error message, error code, and any associated stack traces.
To fix the HTTP response code 422 error in Snowflake, follow these steps:
Analyze the Error Message: Begin by carefully examining the error message provided by the QueryFailureStatus object. It often contains valuable insights into the specific issue encountered during the query execution.
Review Query Syntax and Semantics: Verify the syntax and semantics of the SQL query that triggered the error. Check for any typos, missing or extra quotation marks, incorrect column or table names, or other similar issues that may cause the query to fail.
Validate Data Types: Ensure that the data types of the columns being used in the query are appropriate for the intended operations. Mismatched data types can lead to semantic errors and trigger the HTTP response code 422.
Check for Data Integrity Issues: Examine the data being queried for any anomalies or inconsistencies. Data integrity problems, such as missing or duplicate values, can interfere with query execution and result in the 422 error.
Verify Access Privileges: Confirm that the user executing the query has the necessary privileges to perform the requested operations. Lack of appropriate permissions can lead to semantic errors and trigger the HTTP response code 422.
Review Query Execution Settings: Snowflake provides various query execution settings that can affect the outcome of the query. Check if any specific settings, such as result size limits or time limits, are impacting the query execution. Adjusting these settings appropriately may help resolve the error.
Utilize Snowflake Documentation and Community: Leverage the extensive documentation and community resources available for Snowflake. The official Snowflake documentation offers detailed information about error codes, troubleshooting steps, and best practices. Participating in the Snowflake community forums or reaching out to Snowflake support can also provide valuable insights and guidance.
Test the Query in a Sandbox Environment: If possible, replicate the error in a non-production or sandbox environment. This allows you to experiment with different solutions without the risk of impacting live data. It can help isolate the cause of the error and verify the effectiveness of potential fixes.
Collaborate with Colleagues: Engage with your colleagues, especially those experienced in Snowflake, to seek their expertise. They may have encountered similar issues in the past or possess insights that can assist in resolving the HTTP response code 422 error.
Implement Fixes Incrementally: When attempting to fix the error, it is generally advisable to implement changes incrementally rather than making multiple modifications simultaneously. This approach allows you to identify the specific fix that resolves the issue and minimizes the chances of introducing new problems.
Retest and Monitor: After applying a potential fix, retest the query to confirm that the HTTP response code 422 error no longer occurs. Monitor subsequent query executions to ensure the error does not resurface and that the fix does not have any adverse effects on other aspects of the system.
By following these steps, you can effectively troubleshoot and fix the HTTP response code 422 error in Snowflake. Remember to approach the error resolution process systematically, leveraging available resources, and seeking assistance when needed. With perseverance and careful analysis, you can overcome this error and continue to harness the power of Snowflake for your data analytics needs.
In the world of database management systems, views are powerful tools that allow users to retrieve and manipulate data in a simplified manner. Oracle, one of the leading database vendors, offers two types of views: database views and materialized views. While both serve similar purposes, there are significant differences between them in terms of their functionality, storage, and performance. In this article, we will explore these differences with a focus on Oracle's database views and materialized views, along with an example to illustrate their usage
A) Definition and Functionality:
1. Database View: A database view is a virtual table that is derived from one or more underlying tables or views. It provides a logical representation of the data and can be used to simplify complex queries by predefining joins, filters, and aggregations. Whenever a query is executed against a view, the underlying data is dynamically fetched from the base tables.
2. Materialized View: A materialized view, on the other hand, is a physical copy or snapshot of a database view. Unlike a database view, it stores the result set of a query in a separate table, making it a persistent object. Materialized views are typically used to improve query performance by precomputing and storing the results of expensive and complex queries, reducing the need for re-computation during subsequent queries.
B) Data Storage:
1. Database View: Database views do not store any data on their own. They are stored as a definition or metadata in the database dictionary and do not occupy any additional storage space. Whenever a query is executed against a view, it is processed in real-time by retrieving the data from the underlying tables.
2. Materialized View: Materialized views store their data in physical tables, which are separate from the base tables. This storage mechanism allows for faster data retrieval, as the results of the query are already computed and stored. Materialized views occupy disk space to store their data, and this storage requirement should be considered when designing the database schema.
C) Query Performance:
1. Database View: Database views are advantageous for simplifying complex queries and enhancing data abstraction. However, they may suffer from performance issues when dealing with large datasets or queries involving multiple joins and aggregations. Since the data is fetched from the underlying tables dynamically, the execution time may be slower compared to materialized views.
2. Materialized View: Materialized views excel in terms of query performance. By storing the precomputed results of a query, they eliminate the need for repetitive calculations. As a result, subsequent queries against materialized views can be significantly faster compared to database views. Materialized views are particularly useful when dealing with queries that involve extensive processing or access to remote data sources.
Now, let's consider an example to better understand the differences:
Suppose we have a database with two tables: "Orders" and "Customers." We want to create a view that displays the total order amount for each customer. Here's how we can achieve this using both a database view and a materialized view in Oracle:
Database View:
CREATE VIEW Total_Order_Amount AS
SELECT c.Customer_Name, SUM(o.Order_Amount) AS Total_Amount
FROM Customers c
JOIN Orders o ON c.Customer_ID = o.Customer_ID
GROUP BY c.Customer_Name;
Materialized View:
CREATE MATERIALIZED VIEW MV_Total_Order_Amount
BUILD IMMEDIATE
REFRESH FAST ON COMMIT
AS
SELECT c.Customer_Name, SUM(o.Order_Amount) AS Total_Amount
FROM Customers c
JOIN Orders o ON c.Customer_ID = o.Customer_ID
GROUP BY c.Customer_Name;
In this example, the database view "Total_Order_Amount" does not store any data and retrieves it in real-time when queried. On the other hand, the materialized view "MV_Total_Order_Amount" stores the computed results of the query, enabling faster retrieval in subsequent queries. However, the materialized view needs to be refreshed to synchronize the data with the underlying tables. The "REFRESH FAST ON COMMIT" option ensures that the materialized view is updated automatically when changes are committed to the base tables.
While both database views and materialized views offer a convenient way to retrieve and manipulate data, they differ in their functionality, storage mechanisms, and query performance characteristics. Database views provide a logical representation of the data and are suitable for simplifying complex queries, while materialized views offer improved performance by persistently storing precomputed results. Understanding these differences is crucial for making informed decisions when designing and optimizing database systems in Oracle.
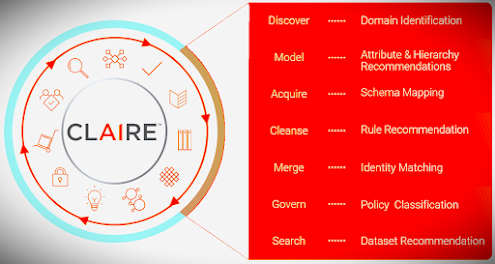
Informatica has developed an AI and machine learning technology called "CLAIRE" (Cloud-scale AI-powered Real-time Engine). CLAIRE is an intelligent metadata-driven engine that powers Informatica's data management products. It uses AI and machine learning techniques to automate various data management tasks and provide intelligent recommendations for data integration, data quality, and data governance.
CLAIRE is designed to analyze large volumes of data, identify patterns, and make data management processes more efficient. It leverages machine learning algorithms to understand data relationships, improve data quality, and enhance data governance practices. By utilizing CLAIRE, Informatica aims to assist organizations in achieving better data-driven decision-making and improving overall data management capabilities.
What are Informatica products in which CLAIRE is used?
CLAIRE, Informatica's AI engine, is integrated into several products and solutions offered by Informatica. While the specific usage and capabilities of CLAIRE may vary across these products, here are some of the key Informatica products where CLAIRE is utilized:
1. Informatica Intelligent Cloud Services: CLAIRE powers various aspects of Informatica's cloud data integration and data management platform. It provides intelligent recommendations for data integration, data quality, and data governance in cloud environments.
2. Informatica PowerCenter: CLAIRE is integrated into Informatica's flagship data integration product, PowerCenter. It enhances PowerCenter with AI-driven capabilities, such as intelligent data mapping, data transformation recommendations, and data quality insights.
3. Informatica Data Quality: CLAIRE plays a significant role in Informatica's Data Quality product. It leverages AI and machine learning to analyze data patterns, identify data quality issues, and provide recommendations for data cleansing and standardization.
4. Informatica Master Data Management (MDM): CLAIRE is utilized in Informatica's MDM solutions to improve master data management processes. It applies AI techniques to match, merge, and consolidate master data, ensuring data accuracy and consistency.
5. Informatica Enterprise Data Catalog: CLAIRE powers the metadata management capabilities of Informatica's Enterprise Data Catalog. It uses AI to automatically discover, classify, and organize metadata across various data sources, enabling users to search and retrieve relevant metadata information.
6. Informatica Axon Data Governance: CLAIRE is employed in Informatica's Axon Data Governance solution. It provides AI-driven insights and recommendations for data classification, data lineage, and data governance policies, helping organizations establish and enforce effective data governance practices.
These are some of the key products where CLAIRE is utilized within the Informatica ecosystem. It's important to note that Informatica may continue to integrate CLAIRE into new and existing products, so it's always advisable to refer to Informatica's official documentation or contact their support for the most up-to-date information on CLAIRE's usage within specific products.