Are you looking for an article about calling Informatica MDM batch jobs? Are you also looking for how to call Informatica jobs using IDQ mapping or maplet? If so, then you reached the right place. In this article, we will see how to call Informatica MDM jobs such as stage, load, tokenization, match, merge, and batch groups using Informatica Data Quality (IDQ) mapping.
A. Introduction
Informatica MDM exposes various operations in the form of APIs and SOAP Web Service. We can call SOAP Web Service in Informatica Data Quality (IDQ) to execute MDM batch jobs. In this article, we will see step by step process how to create Web Service consumer and create mapping or maplet to call the SOAP Web Service.
B. Create Web Service Consumer
We need to create a web service consumer to call MDM SOAP Web Service. To create Web Service Consumer, select Physical Data Object and right-click to add Web Service consumer. A new dialog window will open to select the component. Select it and click next.

Configure Web Service endpoint URL which can be provided by MDM team. You need username and password to access MDM SOAP Web Service.

C. Create MDM Connection
To create MDM connection, go to Windows -> Preferences and select Connections under Web Services component. Provide authentical details as shown in the screen below.
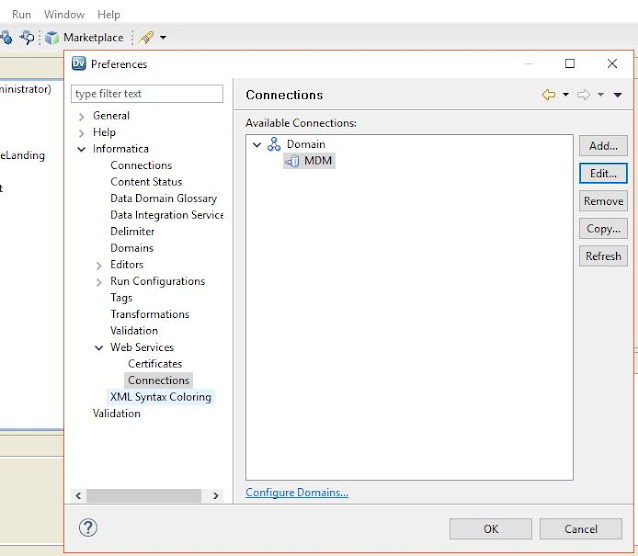
Make sure proper values for Timeout, HTTP Authentication Type, and WS-Security Type are selected. Then test the Web Service connection using 'Test Connection' button.

D. Mapping Overview
The mapping contains source component, input expression, Web Service Consumer transformation, output expression, and target component.

Create a source component as flat file or database table.
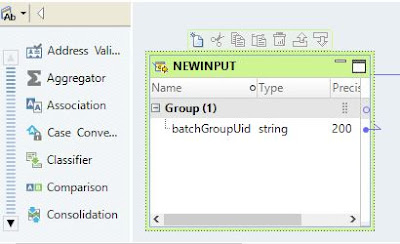
2. Input expression
Create an input expression and translate input values into Web Service-specific values such as orsId, batchGroupUid etc.

3. Web Service Consumer Transformation
Create a web service consumer transformation and pass the input variables.
Verify all the required ports properly automatically populated.

Update the input mapping with proper ports and if any ports are improperly mapped then correct it. Make sure key columns in the target are all mapped with some values from input

Verify the output mapping is correctly populated. Make necessary changes if required.

Make sure the Connection object is properly populated and other relevant properties under the Advanced section.

4. Union Transformation
Combine all the output parameters from web service and create a Union transformation. This is required to populate fault message in the response.

5. Output Expression
Create output expression to map all the attributes from Union transformation and translate it into the output format.

6. Target Component
Create the target component with a flat file or database table to persist the response of Informatica MDM job status and statistics.